En este proyecto vamos a desarrollar un modelo predictivo para identificar clientes con alto riesgo de churn (abandono) en una institución bancaria, utilizando técnicas de Machine Learning
Importación de Datos
Código
# Importamos las libreriaslibrary(data.table)library(tidyverse)source("D:/Joel/Blog/recursos/funciones_aux.R")df <-fread("Churn_Modelling.csv")head(df,5)
creamos una lista de variables para mejor manipulación
Código
index <-c("RowNumber", "CustomerId","Surname")var_num <-c("CreditScore", "Age", "Tenure", "Balance","EstimatedSalary")var_cat <-setdiff(names(df),c(index,var_num,"Exited"))
Cambio de nombres de las columnas
En esta ocasión no vamos a cambiar ningun nombre
Exploración de datos
Primero visualicemos un breve resumen de las variables
Código
summary(df)
RowNumber CustomerId Surname CreditScore
Min. : 1 Min. :15565701 Length:10002 Min. :350.0
1st Qu.: 2501 1st Qu.:15628525 Class :character 1st Qu.:584.0
Median : 5002 Median :15690732 Mode :character Median :652.0
Mean : 5002 Mean :15690933 Mean :650.6
3rd Qu.: 7502 3rd Qu.:15753226 3rd Qu.:718.0
Max. :10000 Max. :15815690 Max. :850.0
Geography Gender Age Tenure
Length:10002 Length:10002 Min. :18.00 Min. : 0.000
Class :character Class :character 1st Qu.:32.00 1st Qu.: 3.000
Mode :character Mode :character Median :37.00 Median : 5.000
Mean :38.92 Mean : 5.012
3rd Qu.:44.00 3rd Qu.: 7.000
Max. :92.00 Max. :10.000
NA's :1
Balance NumOfProducts HasCrCard IsActiveMember
Min. : 0 Min. :1.00 Min. :0.0000 Min. :0.0000
1st Qu.: 0 1st Qu.:1.00 1st Qu.:0.0000 1st Qu.:0.0000
Median : 97199 Median :1.00 Median :1.0000 Median :1.0000
Mean : 76491 Mean :1.53 Mean :0.7055 Mean :0.5149
3rd Qu.:127648 3rd Qu.:2.00 3rd Qu.:1.0000 3rd Qu.:1.0000
Max. :250898 Max. :4.00 Max. :1.0000 Max. :1.0000
NA's :1 NA's :1
EstimatedSalary Exited ModVal
Min. : 11.58 Min. :0.0000 Min. :0.0
1st Qu.: 50983.75 1st Qu.:0.0000 1st Qu.:0.0
Median :100185.24 Median :0.0000 Median :0.0
Mean :100083.33 Mean :0.2038 Mean :0.3
3rd Qu.:149383.65 3rd Qu.:0.0000 3rd Qu.:1.0
Max. :199992.48 Max. :1.0000 Max. :1.0
Notamos que existen valores perdidos o NA’s, los mismos que serán tratados mas adelante
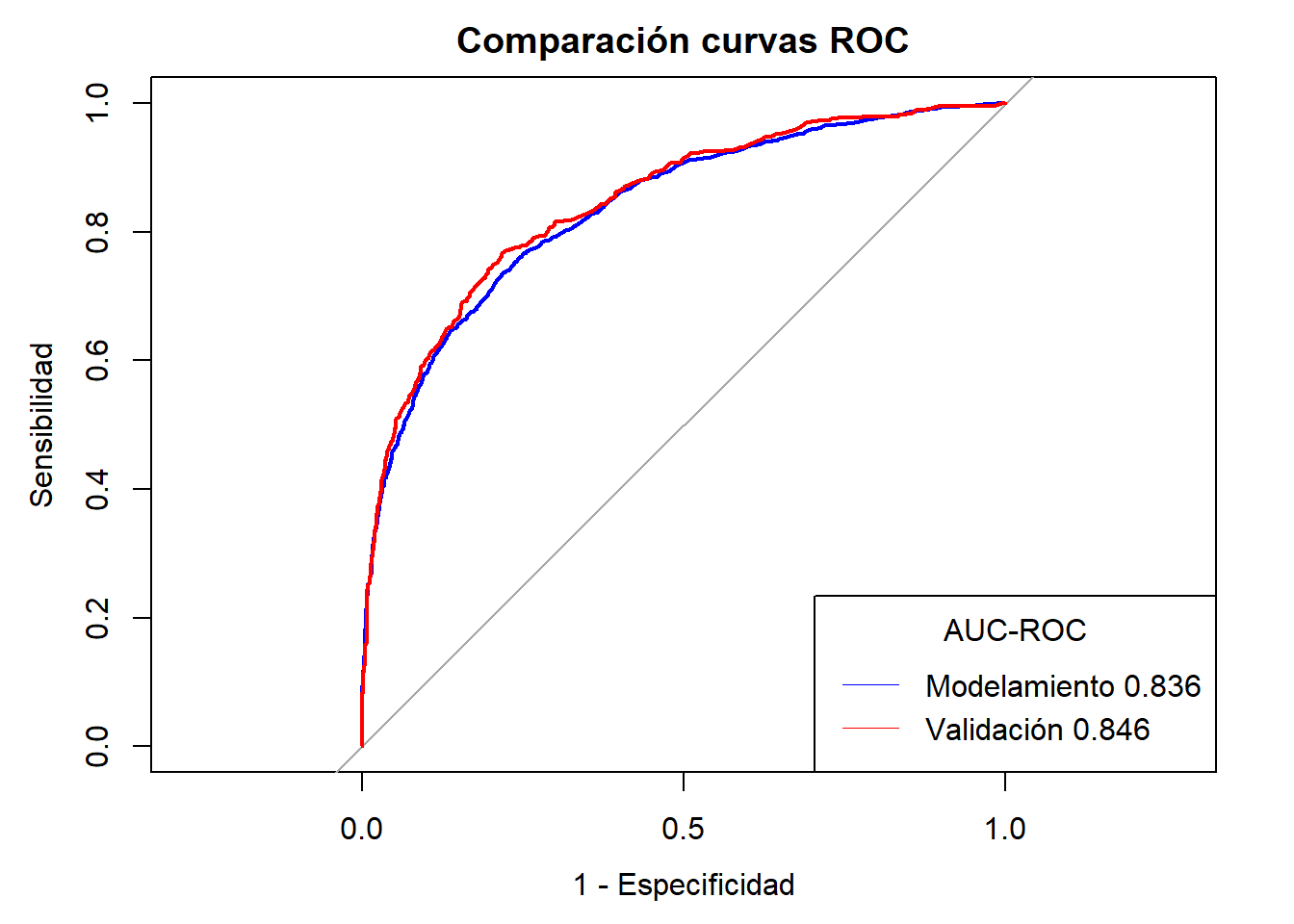
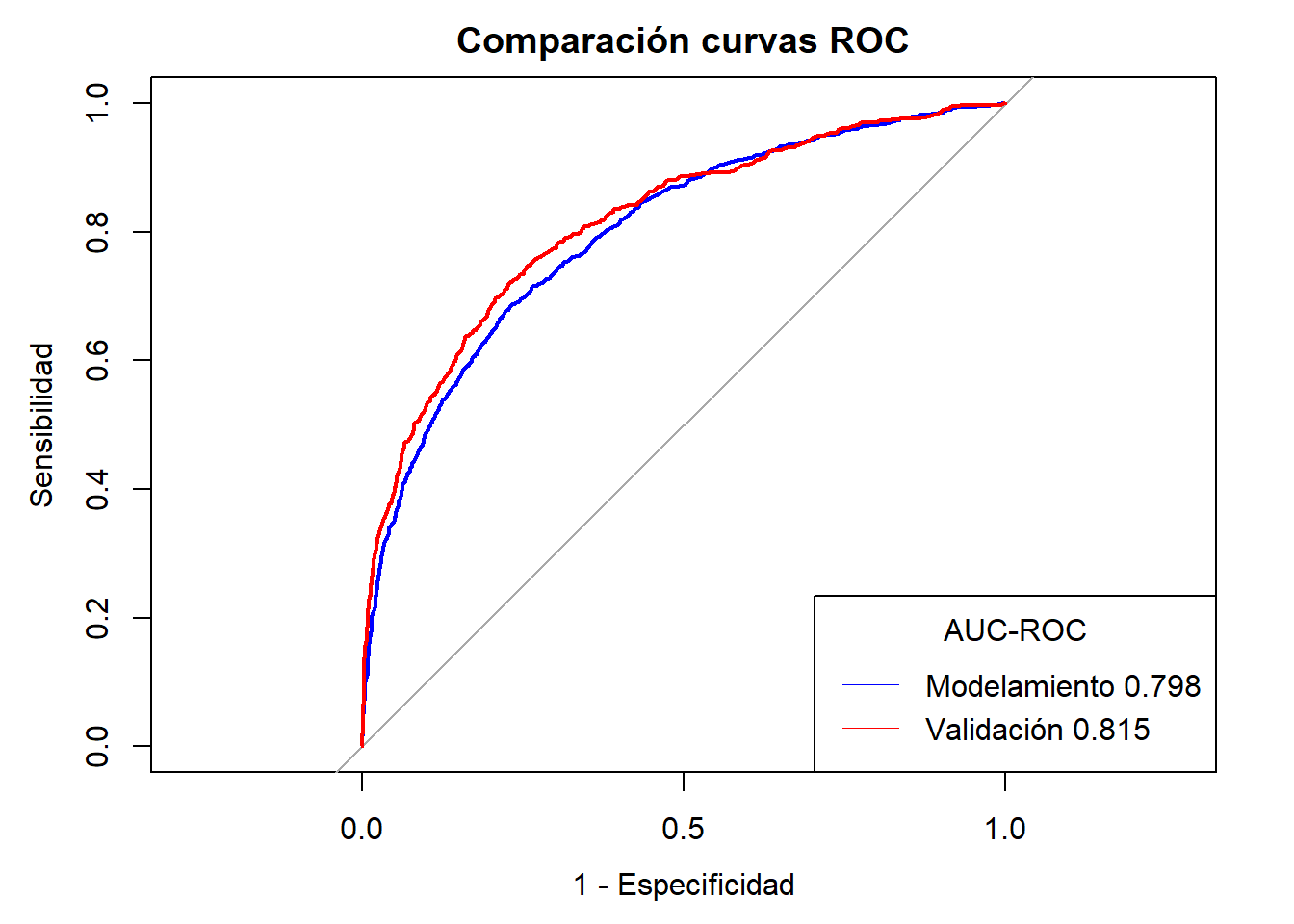
Con la librería scorecard se ha alcanzado un AUC-ROC de validación de 0.815
Ensamble
Creamos y damos formato necesario para utilizar h2o, nota en esta ocasión trabajaremos con las variables binneadas de forma personalizada
Código
# Ejecución del Ensamblelibrary(h2o)h2o.init(ip ="localhost", nthreads =2, max_mem_size ="5G")
Connection successful!
R is connected to the H2O cluster:
H2O cluster uptime: 28 minutes 41 seconds
H2O cluster timezone: America/Guayaquil
H2O data parsing timezone: UTC
H2O cluster version: 3.44.0.3
H2O cluster version age: 8 months and 13 days
H2O cluster name: H2O_started_from_R_joelb_nrn194
H2O cluster total nodes: 1
H2O cluster total memory: 4.91 GB
H2O cluster total cores: 8
H2O cluster allowed cores: 2
H2O cluster healthy: TRUE
H2O Connection ip: localhost
H2O Connection port: 54321
H2O Connection proxy: NA
H2O Internal Security: FALSE
R Version: R version 4.3.3 (2024-02-29 ucrt)
Código
# Establecemos los datos en el formato adecuadovars <-c("Exited", "prbm_NumOfProducts", "prbm_Age", "prbm_IsActiveMember", "prbm_Geography", "prbm_Gender", "prbm_EstimatedSalary")mod_em <-as.h2o(x =setDT(mod)[, vars, with =FALSE])
# Identificamos predictores y respuestay_em <-"Exited"; x_em <-setdiff(names(mod_em), y_em)# Para la clasificación binaria, la respuesta debe ser un factor mod_em[,y_em] <-as.factor(mod_em[,y_em])# Numero de CV folds nfolds <-5# Generaremos el ensamble con 3 modelos (RF + GLM + GBM)
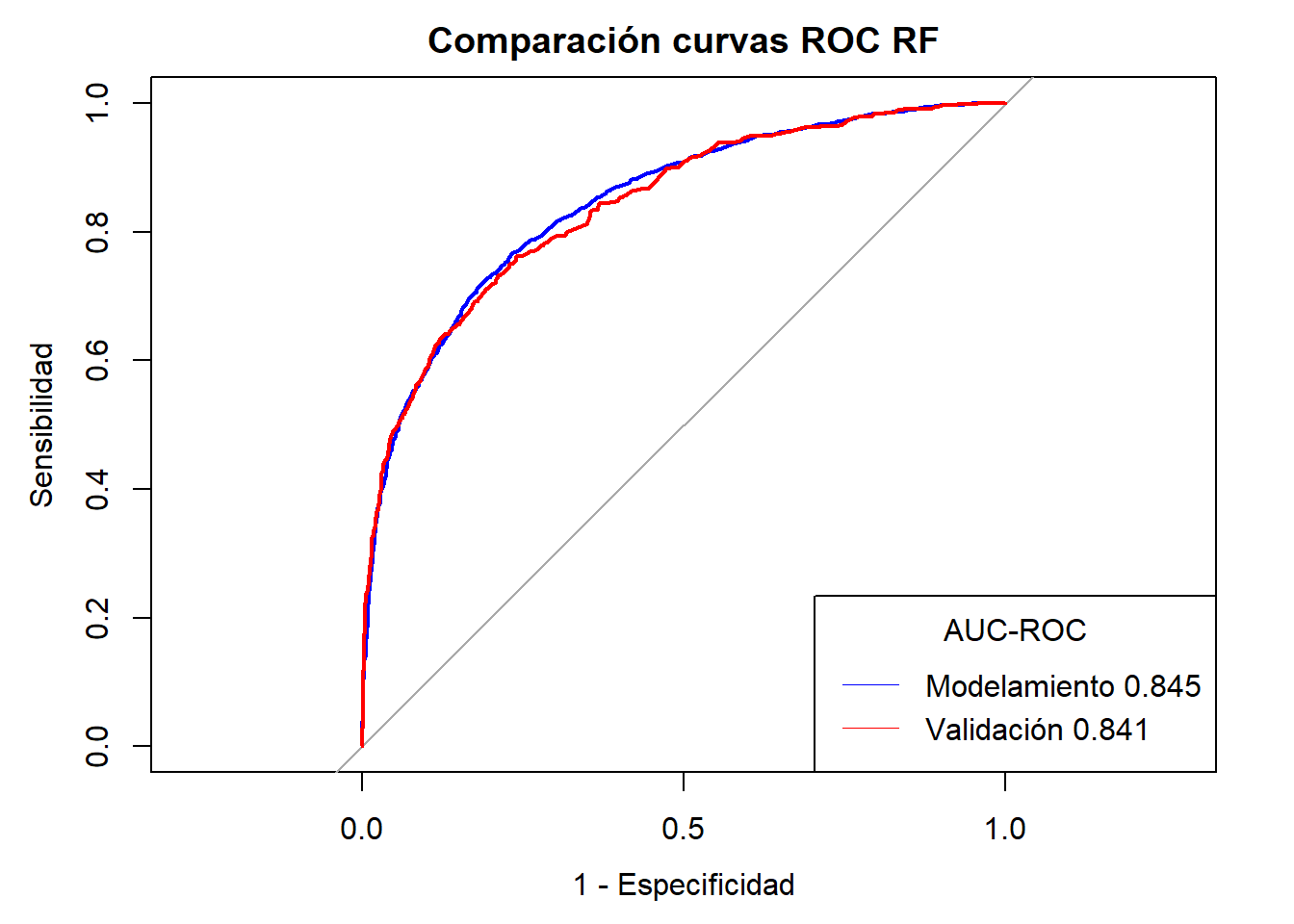
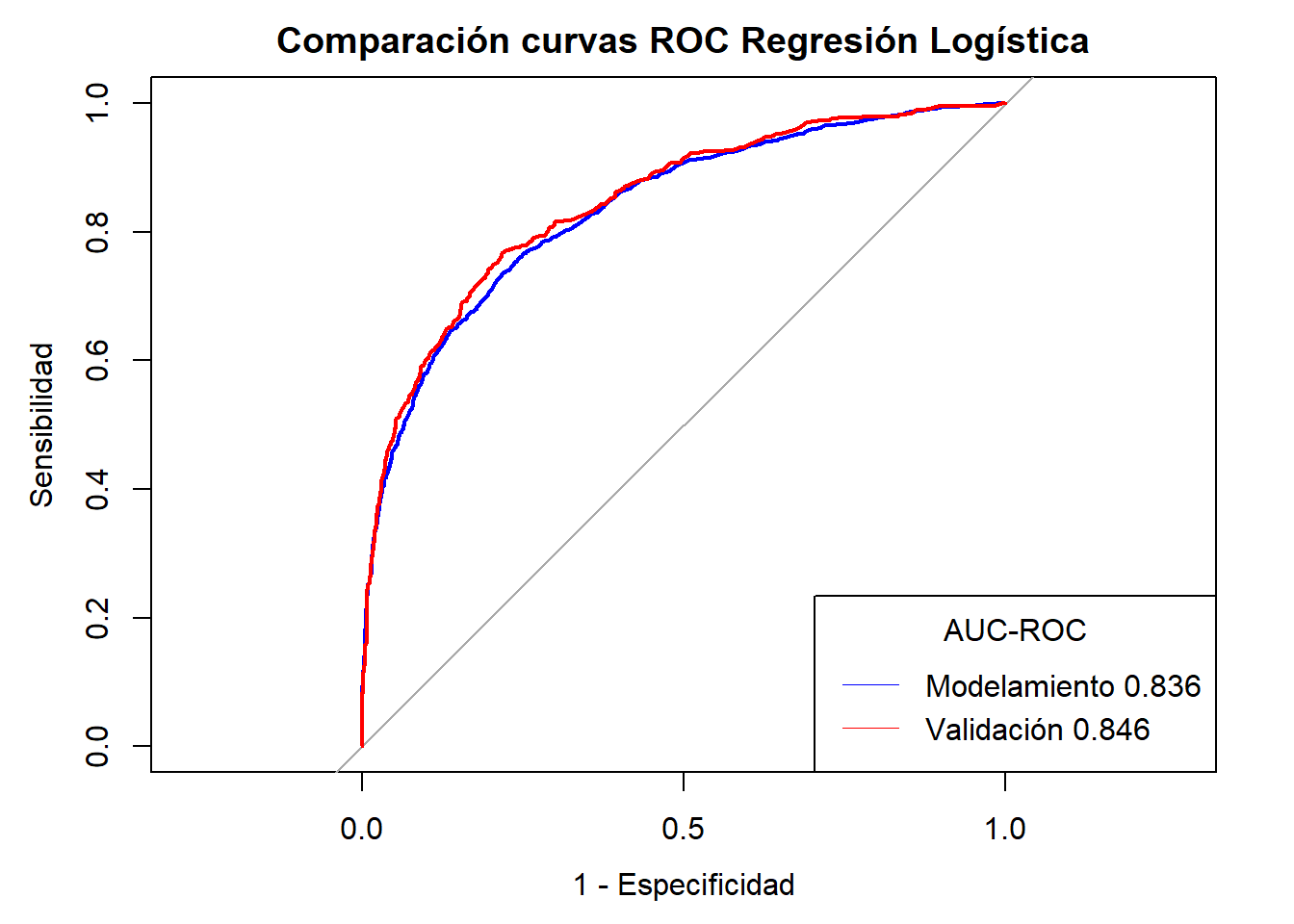
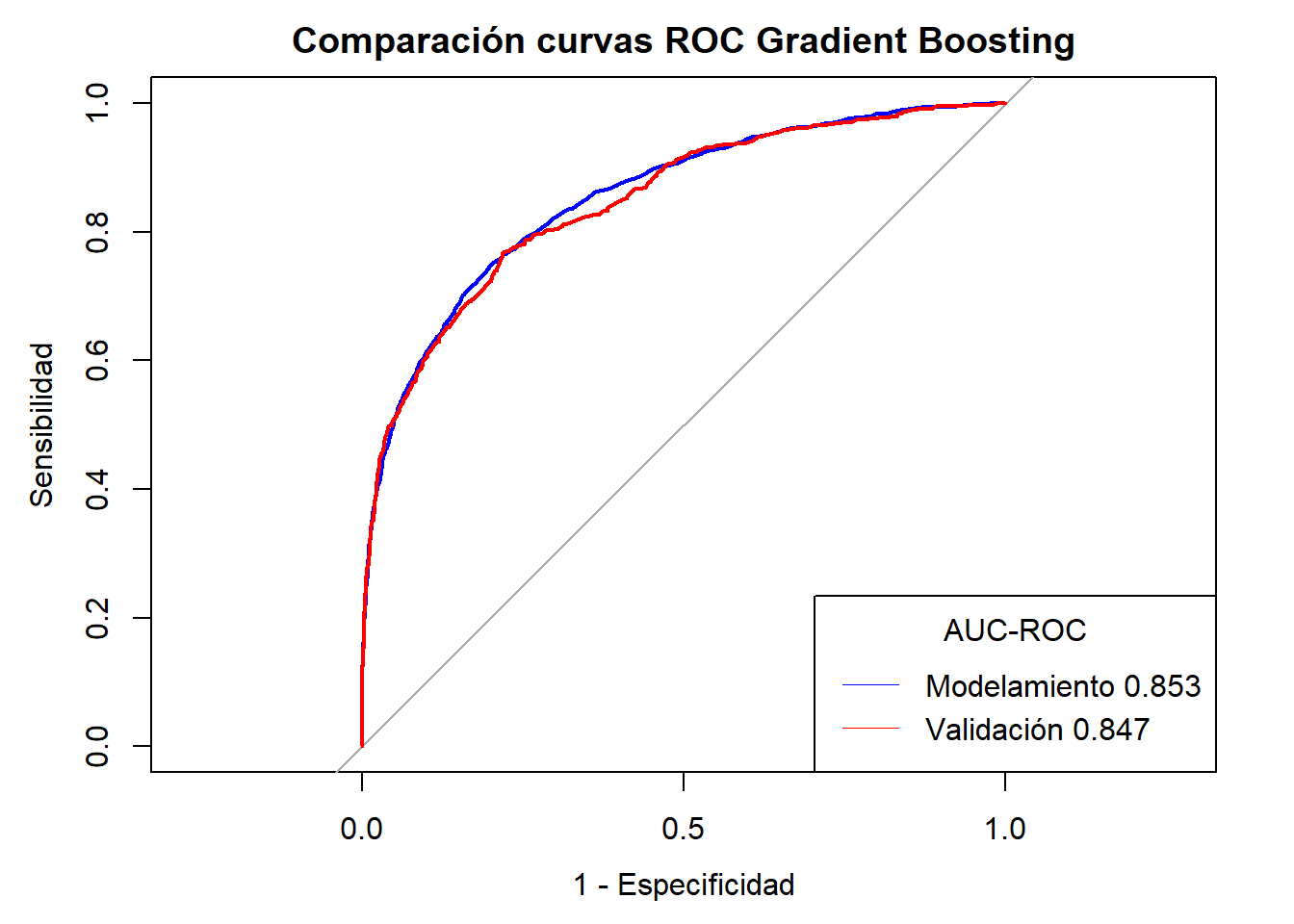
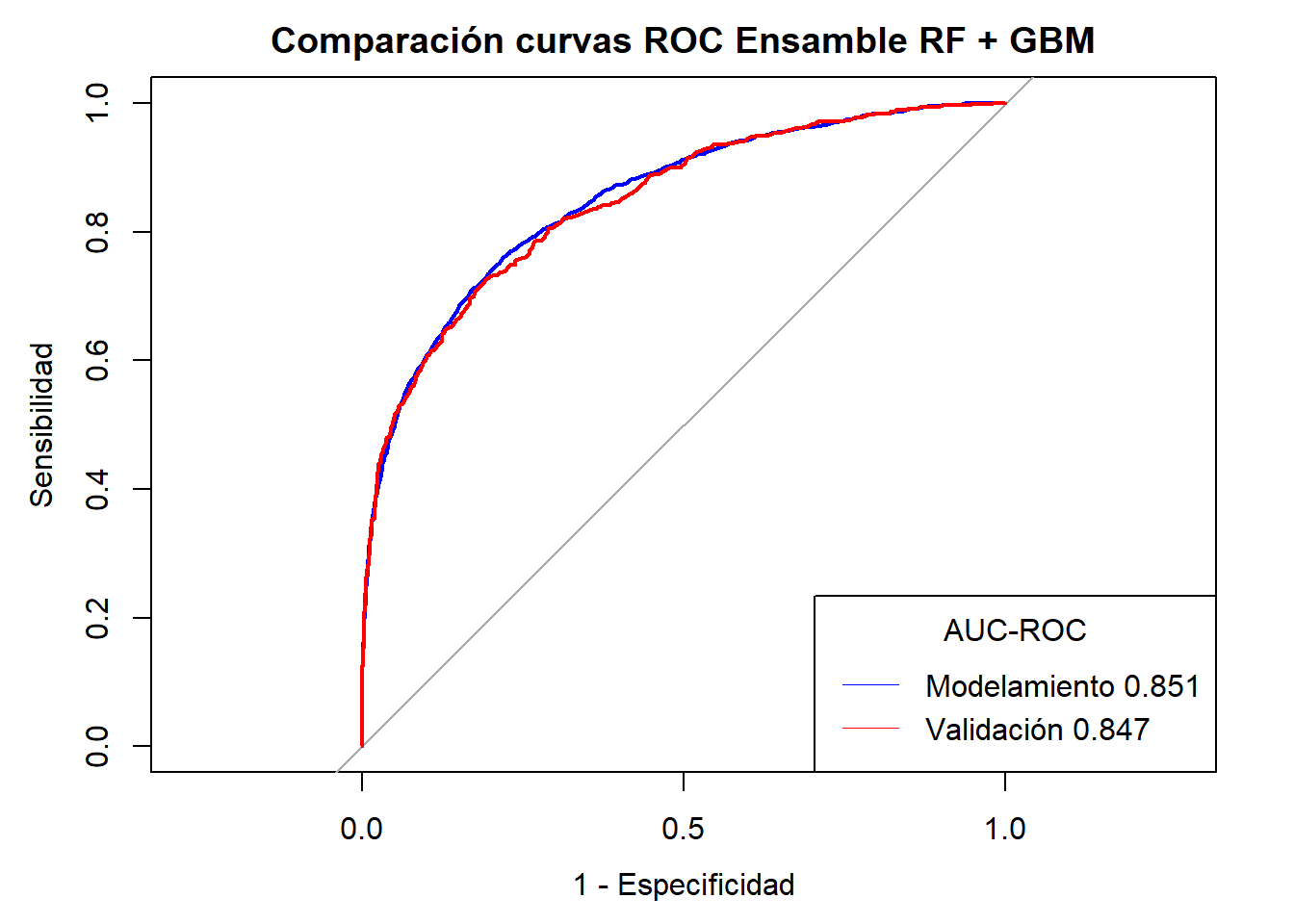
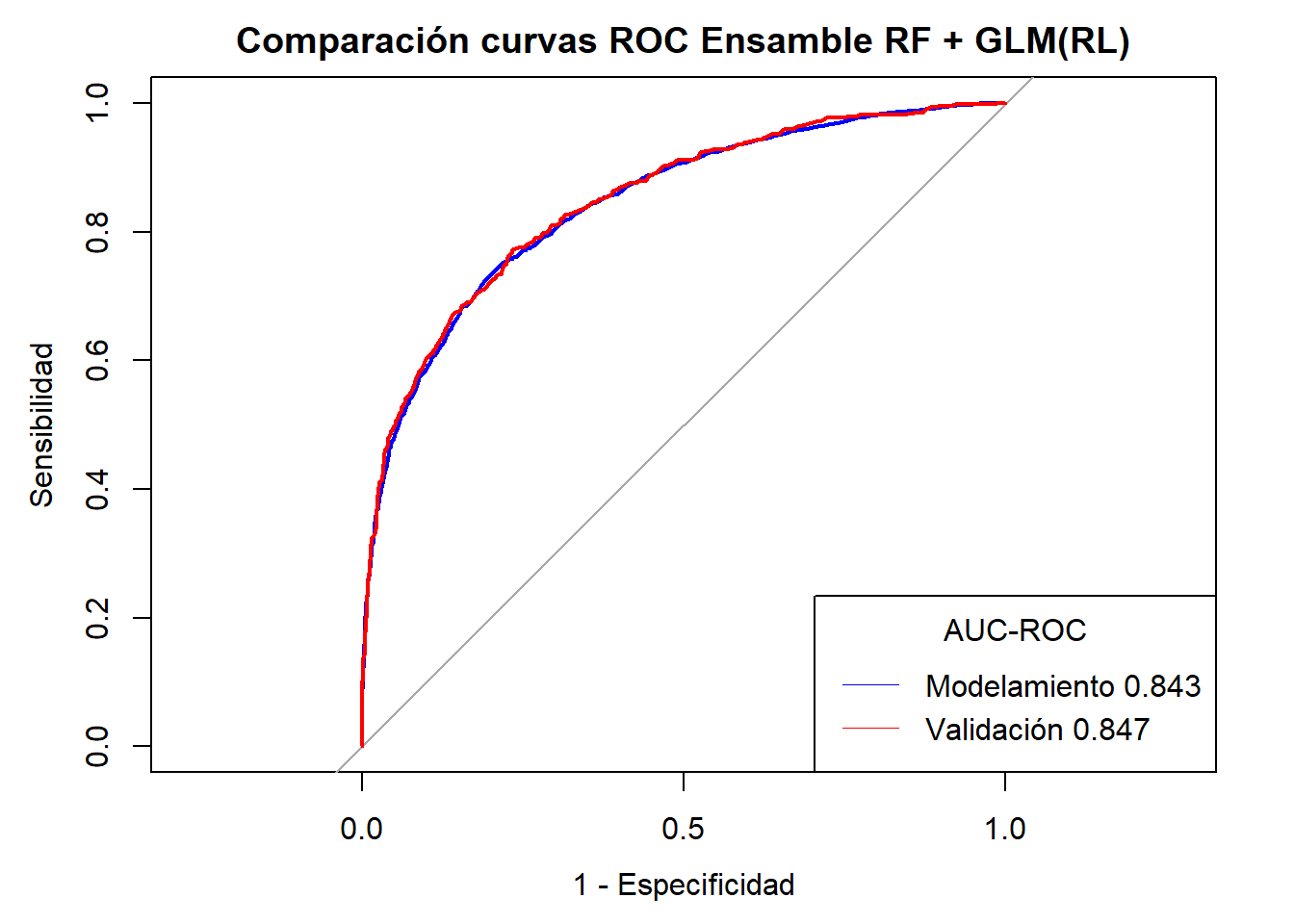
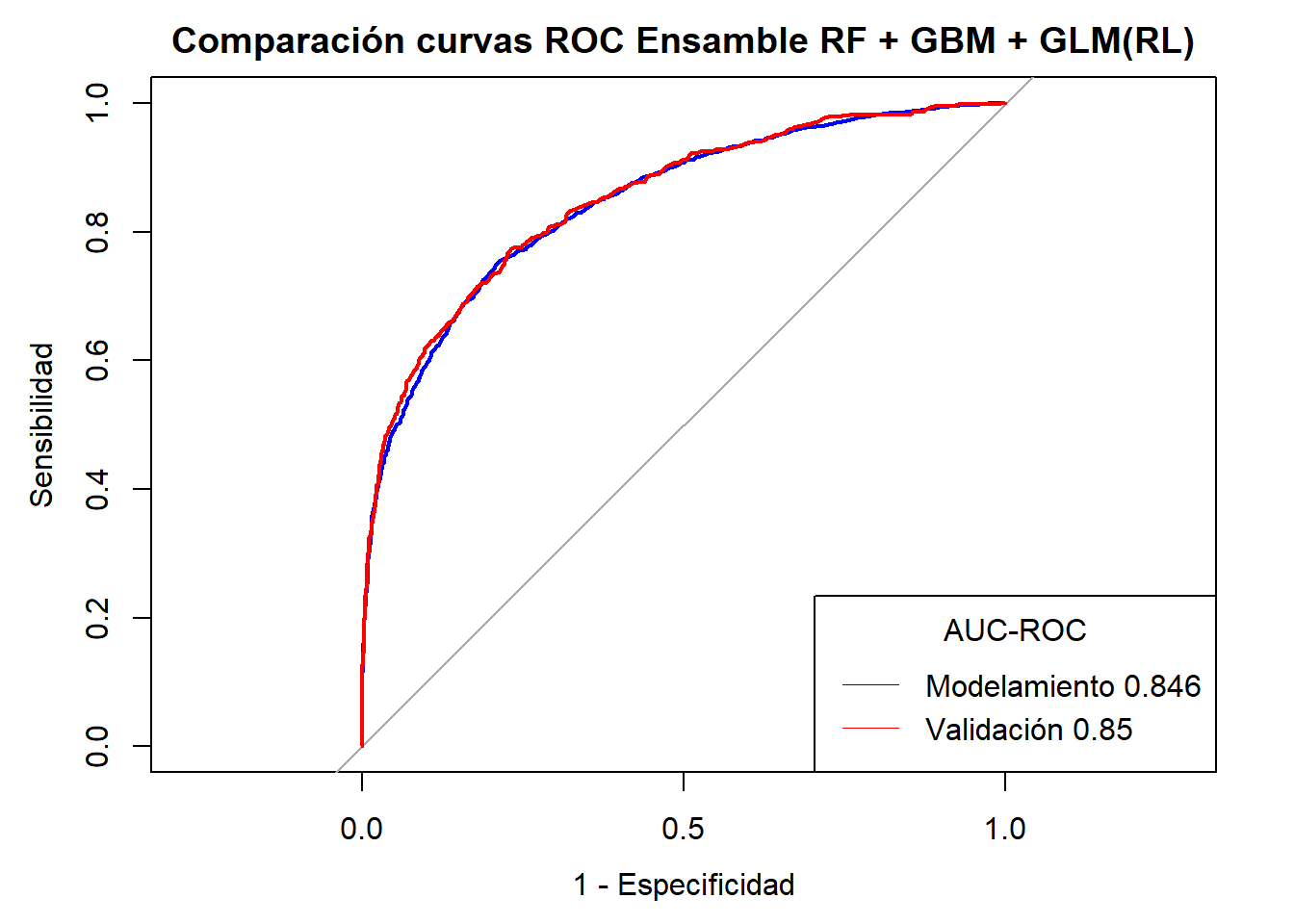
Notemos que en la mayoria de casos se ha alcanzado AUC-ROC \(\geq 0.80\) sin embargo el mejor modelo es el Ensamble de Random Forest + Gradient Boosting Machine + GLM( Regresión Logística) con una AUC-ROC validación de \(0.85\). Sin embargo el modelo también se ve sometido a requerimientos y recursos propios del negocio por lo que puede quedarse fuera y se opte por un modelo menos costoso en cuestión de tiempo y recursos.
Recomendaciones
En esta ocasión no hemos recurrido a una automatización completa del proceso de creación del modelo por lo que se podría explorar la creación de ensambles partiendo de las variables binneadas por optimal binning.
Ejecutar el código
---title: Churn Rate (Tasa de Abandono)author: Joel Burbanodate: 08-27-2024categories: [R, Machine Learning]---En este proyecto vamos a desarrollar un modelo predictivo para identificar clientes con alto riesgo de churn(abandono) en una institución bancaria, utilizando técnicas de Machine Learning # Importación de Datos```{r}# Importamos las libreriaslibrary(data.table)library(tidyverse)source("D:/Joel/Blog/recursos/funciones_aux.R")df <-fread("Churn_Modelling.csv")head(df,5)```breve revisión a la variable dependiente```{r}df[, .N, by = Exited]```Notamos que la data esta desbalanceada con el grupo mayoritario 1 que son las personas que abandonan* 0 No abandona* 1 Abandona# Particionamos la data en conjuntos Train / Test```{r}# Base de modelamiento / validacionset.seed(95)marca <-sample(1:nrow(df), size =floor(0.7*nrow(df)), replace =FALSE)df[, ModVal :=1:nrow(df)]df[, ModVal :=ifelse(ModVal %in% marca, 0, 1)]df[, .N, by = ModVal]df[, table(Exited, ModVal, useNA ="always")]```# Análisis Exploratorio ## Tipo de datos```{r}str(df)```creamos una lista de variables para mejor manipulación```{r}index <-c("RowNumber", "CustomerId","Surname")var_num <-c("CreditScore", "Age", "Tenure", "Balance","EstimatedSalary")var_cat <-setdiff(names(df),c(index,var_num,"Exited"))```## Cambio de nombres de las columnasEn esta ocasión no vamos a cambiar ningun nombre## Exploración de datosPrimero visualicemos un breve resumen de las variables```{r}summary(df)```Notamos que existen valores perdidos o NA's, los mismos que serán tratados mas adelante## Evaluación de valores nulos```{r}# tratamiento NA's df <- df[!(is.na(HasCrCard) ==TRUE),]df <- df[!(is.na(IsActiveMember) ==TRUE),]df <- df[!(is.na(Age) ==TRUE),]sum(is.na(df))```## Valores duplicados```{r}df <-unique(df)```## Proporción del variable dependiente```{r}df[, round(.N /nrow(df),3), by = Exited]```# Seleccion de Variables (KS / VI)```{r}# KS VI# Sujetos buenos y malos para calculo de KSmod <- df[ModVal ==0& Exited %in%c(0,1)]val <- df[ModVal ==1]# identificación de variables con alto porcentaje de NA'sporc <-sort(sapply(mod, porcNA), decreasing =TRUE)PorcentajeNA <-data.frame(names(porc), as.numeric(porc))colnames(PorcentajeNA) <-c("Var", "Por")dvars <-setdiff(colnames(mod), names(porc)[porc >0.3])# tratamiento NA's df <- df[!(is.na(HasCrCard) ==TRUE),]df <- df[!(is.na(IsActiveMember) ==TRUE),]mod <- df[ModVal ==0& Exited %in%c(0,1)]val <- df[ModVal ==1]# Identificación de variables constantesdvars <- dvars[!unname(unlist(sapply(mod[,dvars, with =FALSE], constante)))]# Ejecución de KS & VIvnum <-colnames(mod)[unname(sapply(mod, class)) %in%c("numeric", "integer") ]vcat <-colnames(mod)[unname(sapply(mod, class)) %in%c("character", "logical")]dnum <- mod[, vnum, with =FALSE]dcat <- mod[, vcat, with =FALSE]VI <-sort(sapply(dcat, TestVI, y = mod$Exited), decreasing = T)dVI <-data.frame(names(VI), VI)colnames(dVI) <-c("Variable", "VI"); rownames(dVI) <-NULLdVI``````{r}# Calculo de KS sobre variables numericasKS <-sapply(seq_along(dnum), function(i){TestKS(dnum[[i]], mod$Exited)})dKS <-data.frame(colnames(dnum), KS); dKS <- dKS[order(dKS$KS, decreasing =TRUE),]colnames(dKS) <-c("Variable", "KS"); rownames(dKS) <-NULLdKS```Seleccionamos las variables con valores altos de KS / VI# Creación de Features para el modelo## Creación de features personalizada ```{r}# Construcción de variables y discretización df[,prbm_NumOfProducts :=ifelse(NumOfProducts <1.5, 0.2776061,ifelse(NumOfProducts <2.5, 0.0800000, 0.8744770))]df[,prbm_Age :=ifelse(Age <42.5, 0.1208350,ifelse(Age <46.5, 0.3450704,ifelse(Age <57.5, 0.5261364, 0.3356808)))]df[, prbm_IsActiveMember :=ifelse(IsActiveMember <0.5, 0.1451298,0.2732064)]df[, prbm_Geography :=ifelse(Geography =="France", 0.1667147,ifelse(Geography =="Spain",0.1624077, 0.3327684))]df[, prbm_Balance :=ifelse(Balance <1884.5, 0.1368209, 0.2466209)]df[, prbm_Gender :=ifelse(Gender =="Male", 0.1714436 , 0.2507042)]df[, prbm_CreditScore :=ifelse(CreditScore <=407.5, 0.94444444 ,0.20573066)]df[, prbm_EstimatedSalary :=ifelse(EstimatedSalary <=25000, 0.2031063,ifelse(EstimatedSalary <=35000, 0.2156863,ifelse(EstimatedSalary <=60000, 0.1944134,ifelse(EstimatedSalary <=75000, 0.2189239,ifelse(EstimatedSalary <=85000, 0.1789474,ifelse(EstimatedSalary <=155000, 0.1990913,ifelse(EstimatedSalary <=185000, 0.2301815, 0.1965649)))))) )]# Generación de muestras para el performance del modelomod <- df[ModVal ==0& Exited %in%c(0,1)]val <- df[ModVal ==1]```### Regresión Logística```{r}# Regresión logisticaformula <-"Exited ~ prbm_NumOfProducts + prbm_Age + prbm_IsActiveMember + prbm_Geography + prbm_Gender + prbm_EstimatedSalary"modelo <-glm(formula =as.formula(formula), family =binomial("logit"), data = mod)summary(modelo)``````{r}nom_vars <-all.vars(terms(modelo))[-1]res <-cor(setDT(mod)[, ..nom_vars])reseigen(res)sqrt( head(eigen(res)$values,1) /tail(eigen(res)$values,1)) # calculo IC > 5 indicios multicolinealidaddf[, Y:= modelo$coefficients[1] +Reduce(`+`, Map(function(var, coef) get(var) * coef, names(modelo$coefficients[-1]), modelo$coefficients[-1]))]df[, RL := (1/ (1+exp(Y)))]#quantile(df$RL, probs = seq(0 , 1, by = 0.01), na.rm = TRUE)mod <- df[ModVal ==0& Exited %in%c(0,1)]val <- df[ModVal ==1]# Estimación Probabilidadesres_mod <-data.table(Var = mod$Exited, RL = mod$RL)res_val <-data.table(Var = val$Exited, RL = val$RL)``````{r}# Gráficas ROClibrary(pROC)objroc1 <-roc(res_mod$Var, res_mod$RL, auc=T, ci=T)plot(objroc1, col="blue", xlab="1 - Especificidad", ylab="Sensibilidad", main="Comparación curvas ROC", legacy.axes =TRUE)objroc2 <-roc(res_val$Var, res_val$RL, auc=T, ci=T)plot(objroc2, col="red", add=TRUE)legend("bottomright", legend=c(paste("Modelamiento",round(objroc1$auc, 3)), paste("Validación", round(objroc2$auc, 3))), col=c("blue", "red"), lwd=0.5, title ="AUC-ROC")#legend("topright", legend = c(round(objroc1$auc, 3), round(objroc2$auc, 3)), col = c("blue", "red"), lwd = 0.2 , title = "AUC-ROC")```Con estas features se ha alcanzado un AUC-ROC con la data de validación de `r round(objroc2$auc, 3)`## Optimal binningCreando los features y bins con la libreria `scorecard````{r}#install.packages("scorecard")library(scorecard)vars <-c("NumOfProducts", "Age", "IsActiveMember", "Geography", "Gender", "EstimatedSalary")bins <-woebin(df, y ="Exited", x = vars)print(bins)``````{r}df_bineed <-woebin_ply(df,bins = bins)head(df_bineed, 5)``````{r}# Generación de muestras para el performance del modelomod <- df_bineed[ModVal ==0& Exited %in%c(0,1)]val <- df_bineed[ModVal ==1]# Regresión logisticaformula <-"Exited ~ NumOfProducts_woe + Age_woe + IsActiveMember_woe + Geography_woe + Gender_woe + EstimatedSalary_woe"modelo <-glm(formula =as.formula(formula), family =binomial("logit"), data = mod)summary(modelo)``````{r}nom_vars <-all.vars(terms(modelo))[-1]res <-cor(setDT(mod)[, ..nom_vars])reseigen(res)sqrt( head(eigen(res)$values,1) /tail(eigen(res)$values,1)) # calculo IC > 5 indicios multicolinealidaddf_bineed[, Y:= modelo$coefficients[1] +Reduce(`+`, Map(function(var, coef) get(var) * coef, names(modelo$coefficients[-1]), modelo$coefficients[-1]))]df_bineed[, RL := (1/ (1+exp(Y)))]#quantile(df_bineed$RL, probs = seq(0 , 1, by = 0.01))mod <- df_bineed[ModVal ==0& Exited %in%c(0,1)]val <- df_bineed[ModVal ==1]# Estimación Probabilidadesres_mod <-data.table(Var = mod$Exited, RL = mod$RL)res_val <-data.table(Var = val$Exited, RL = val$RL)``````{r}# Gráficas ROC#library(pROC)objroc1 <-roc(res_mod$Var, res_mod$RL, auc=T, ci=T)plot(objroc1, col="blue", xlab="1 - Especificidad", ylab="Sensibilidad", main="Comparación curvas ROC", legacy.axes =TRUE)objroc2 <-roc(res_val$Var, res_val$RL, auc=T, ci=T)plot(objroc2, col="red", add=TRUE)legend("bottomright", legend=c(paste("Modelamiento",round(objroc1$auc, 3)), paste("Validación", round(objroc2$auc, 3))), col=c("blue", "red"), lwd=0.5, title ="AUC-ROC")```Con la librería `scorecard` se ha alcanzado un AUC-ROC de validación de `r round(objroc2$auc, 3)`## EnsambleCreamos y damos formato necesario para utilizar `h2o`, nota en esta ocasión trabajaremos con las variables binneadas de forma personalizada```{r}# Ejecución del Ensamblelibrary(h2o)h2o.init(ip ="localhost", nthreads =2, max_mem_size ="5G")# Establecemos los datos en el formato adecuadovars <-c("Exited", "prbm_NumOfProducts", "prbm_Age", "prbm_IsActiveMember", "prbm_Geography", "prbm_Gender", "prbm_EstimatedSalary")mod_em <-as.h2o(x =setDT(mod)[, vars, with =FALSE])# Identificamos predictores y respuestay_em <-"Exited"; x_em <-setdiff(names(mod_em), y_em)# Para la clasificación binaria, la respuesta debe ser un factor mod_em[,y_em] <-as.factor(mod_em[,y_em])# Numero de CV folds nfolds <-5# Generaremos el ensamble con 3 modelos (RF + GLM + GBM)```## Random Forest```{r}# Train & Cross- validate a RFmy_rf <-h2o.randomForest(x = x_em,y = y_em,model_id ="RF",training_frame = mod_em,ntrees =300,min_rows =50,mtries =5,nfolds = nfolds,fold_assignment ="Stratified",keep_cross_validation_predictions =TRUE,seed =95)h2o.confusionMatrix(my_rf)```## Gradient Boosting Machine```{r}# Train & Cross-validate a GBMmy_gbm <-h2o.gbm(x = x_em,y = y_em,model_id ="GBM",training_frame = mod_em,distribution ="bernoulli",ntrees =300,max_depth =5,min_rows =50,learn_rate =0.02,nfolds = nfolds,fold_assignment ="Stratified",keep_cross_validation_predictions =TRUE,seed =95)h2o.confusionMatrix(my_gbm)```## Regresión Logística```{r}# Train & Cross-validate a GLMmy_glm <-h2o.glm(x = x_em,y = y_em,model_id ="GLM",training_frame = mod_em,alpha =0.1, # penaliza inclusión excesiva de variablesremove_collinear_columns =TRUE,nfolds = nfolds,fold_assignment ="Stratified",keep_cross_validation_predictions =TRUE,seed =95)h2o.confusionMatrix(my_glm)```## Ensamble RF + GBM```{r}# Train ensamblee1m <-h2o.stackedEnsemble(x = x_em,y = y_em,training_frame = mod_em,model_id ="Ensamble_1m",metalearner_algorithm ="deeplearning",base_models =list(my_rf, my_gbm))```## Ensamble RF + RL```{r}e2m <-h2o.stackedEnsemble(x = x_em,y = y_em,training_frame = mod_em,model_id ="Ensamble_2m",metalearner_algorithm ="deeplearning",base_models =list(my_rf, my_glm))```Ensamble RF + RL + GBM ```{r}e3m <-h2o.stackedEnsemble(x = x_em,y = y_em,training_frame = mod_em,model_id ="Ensamble3m",metalearner_algorithm ="deeplearning",base_models =list(my_rf, my_gbm, my_glm))```## Predicciones ```{r}# Realizamos los predicciones sobre la muestra de modelamiento / validaciónmod_em <-as.h2o(x =setDT(mod)[, vars, with =FALSE])val_em <-as.h2o(x =setDT(val)[, vars, with =FALSE])mod_em[,y_em] <-as.factor(mod_em[, y_em])val_em[,y_em] <-as.factor(val_em[, y_em])res_f <-function(valida, resul){ res <-data.frame(Exited = valida$Exited,Exited_p =as.data.frame(resul)[,3],0)return(res)} roc_graf <-function(res_mod, res_val, name=""){objroc1 <-roc(res_mod$Exited, res_mod$Exited_p, auc=T, ci=T)plot(objroc1, col="blue", xlab="1 - Especificidad", ylab="Sensibilidad", main=paste("Comparación curvas ROC",name), legacy.axes =TRUE)objroc2 <-roc(res_val$Exited, res_val$Exited_p, auc=T, ci=T)plot(objroc2, col="red", add=TRUE)legend("bottomright", legend=c(paste("Modelamiento",round(objroc1$auc, 3)), paste("Validación", round(objroc2$auc, 3))), col=c("blue", "red"), lwd=0.5, title ="AUC-ROC")}```## Curva ROC RF```{r}# Random Forestmod_rf <-setDT(res_f(mod, h2o.predict(my_rf, newdata = mod_em)))val_rf <-setDT(res_f(val, h2o.predict(my_rf, newdata = val_em)))roc_graf(mod_rf,val_rf, "RF")```## Curva ROC RL```{r}# Regresión Logísticamod_glm <-setDT(res_f(mod, h2o.predict(my_glm, newdata = mod_em)))val_glm <-setDT(res_f(val, h2o.predict(my_glm, newdata = val_em)))roc_graf(mod_glm,val_glm, "Regresión Logística")```## Curva ROC GBM```{r}# Gradient Boosting mod_gbm <-setDT(res_f(mod, h2o.predict(my_gbm, newdata = mod_em)))val_gbm <-setDT(res_f(val, h2o.predict(my_gbm, newdata = val_em)))roc_graf(mod_gbm,val_gbm, "Gradient Boosting")```## Curva ROC RF + GBM```{r}# Ensamble RF + GBMmod_e1m <-setDT(res_f(mod, h2o.predict(e1m, newdata = mod_em)))val_e1m <-setDT(res_f(val, h2o.predict(e1m, newdata = val_em)))roc_graf(mod_e1m,val_e1m, "Ensamble RF + GBM")```## Curva ROC RF + RL```{r}# Ensamble GLM +RFmod_e2m <-setDT(res_f(mod, h2o.predict(e2m, newdata = mod_em)))val_e2m <-setDT(res_f(val, h2o.predict(e2m, newdata = val_em)))roc_graf(mod_e2m,val_e2m, "Ensamble RF + GLM(RL)")```## Curva ROC RL + RF + GBM```{r}# Ensamble GLM + RF + GBMmod_e3m <-setDT(res_f(mod, h2o.predict(e3m, newdata = mod_em)))val_e3m <-setDT(res_f(val, h2o.predict(e3m, newdata = val_em)))roc_graf(mod_e3m,val_e3m, "Ensamble RF + GBM + GLM(RL)")```# Conclusiones * Notemos que en la mayoria de casos se ha alcanzado AUC-ROC $\geq 0.80$ sin embargo el mejor modelo es el Ensamble de Random Forest + Gradient Boosting Machine + GLM( Regresión Logística) con una AUC-ROC validación de $0.85$. Sin embargo el modelo también se ve sometido a requerimientos y recursos propios del negocio por lo que puede quedarse fuera y se opte por un modelo menos costoso en cuestión de tiempo y recursos.# Recomendaciones* En esta ocasión no hemos recurrido a una automatización completa del proceso de creación del modelo por lo que se podría explorar la creación de ensambles partiendo de las variables binneadas por optimal binning.